
What is Normalization?
Have you ever wondered why some data sets look neat and tidy, while others look messy and chaotic? Or why some databases can store and retrieve information faster and more efficiently than others? The answer lies in a process called normalization, which is a way of organizing data to avoid redundancy, inconsistency, and confusion.
How Does Data Normalization Work?
Data normalization is a process of organizing data in a way that avoids duplication, inconsistency, and confusion. It involves dividing data into smaller and simpler units, called tables, and linking them by using common attributes, called keys. The goal of data normalization is to make data easier to store, manage, and analyze.
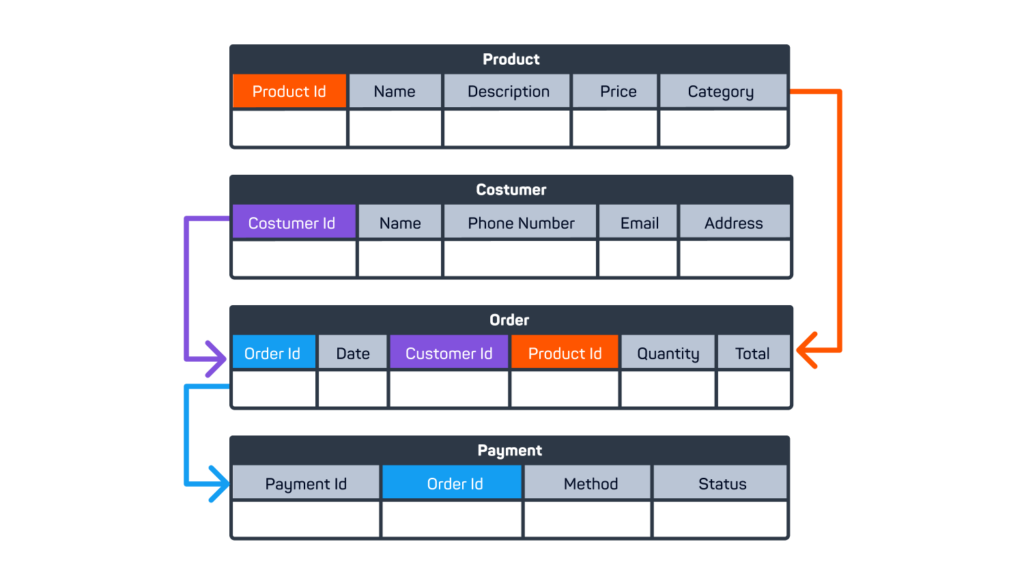
One real-world example of data normalization is how online retailers store and manage their product inventory, customer orders, and payment information. Instead of having one large table that contains all the information, they can have several smaller tables that contain only the relevant information for each entity, such as products, customers, orders, and payments.
For example, a product table can have attributes like product ID, name, description, price, and category. A customer table can have attributes like customer ID, name, email, address, and phone number. An order table can have attributes like order ID, date, customer ID, product ID, quantity, and total. A payment table can have attributes like payment ID, order ID, method, and status. These tables can be linked by using the common attributes, such as customer ID and order ID, to retrieve and combine the information as needed. This way, the data is normalized and more efficient.
What is a KEY in SQL?
In SQL, a key is an attribute or a set of attributes that uniquely identifies a record in a table. Keys are used to enforce data integrity and to establish relationships between tables.
There are two main types of keys in SQL: primary keys and foreign keys.
A primary key is a key that uniquely identifies each record in a table. It cannot contain null values and must be unique for each record. A table can have only one primary key, which can be a single attribute or a combination of attributes. For example, in a customer table, the customer ID can be the primary key.
A foreign key is a key that refers to the primary key of another table. It is used to create a relationship between two tables and to enforce referential integrity. A table can have multiple foreign keys, which can be a single attribute or a combination of attributes. For example, in an order table, the customer ID can be a foreign key that refers to the primary key of the customer table.
The main difference between a primary key and a foreign key is that a primary key uniquely identifies each record in a table, while a foreign key refers to the primary key of another table.
- A primary key cannot contain null values, while a foreign key can contain null values.
- A table can have only one primary key, but it can have multiple foreign keys.
Types of Normal Forms
The main data normalization forms are:
- First Normal Form (1NF): Each attribute (column) of a table (relation) should contain only one value, and each record (row) should be unique.
One possible table example for the 1NF is:
| Customer ID | Name | Phone | |
| 101 | Alice | alice@example.com | 123-456-7890 |
| 102 | Bob | bob@example.com | 234-567-8901 |
| 103 | Charlie | charlie@example.com | 345-678-9012 |
This table is in 1NF because each attribute contains only one value, and each record is unique. There are no repeating groups or composite values in any attribute. The customer ID is the primary key that identifies each record.
- Second Normal Form (2NF): Each attribute of a table should depend on the whole primary key (a unique identifier for each record), and not on a part of it.
One possible table example for the 2NF is:
| Order ID | Customer ID | Product ID | Quantity | Price |
| 201 | 101 | 301 | 2 | 20 |
| 202 | 102 | 302 | 1 | 30 |
| 203 | 103 | 303 | 3 | 40 |
This table is in 2NF because each attribute depends on the whole primary key (Order ID), and not on a part of it. There are no partial dependencies between attributes and the primary key. The Order ID is the primary key that uniquely identifies each record, and the Customer ID and Product ID are foreign keys that refer to the primary keys of the Customer and Product tables, respectively.
- Third Normal Form (3NF): Each attribute of a table should depend only on the primary key, and not on any other attribute.
One possible table example for the 3NF is:
| Order ID | Customer ID | Product ID | Quantity | Price |
| 201 | 101 | 301 | 2 | 20 |
| 202 | 102 | 302 | 1 | 30 |
| 203 | 103 | 303 | 3 | 40 |
This table is in 3NF because each attribute depends only on the primary key (Order ID), and not on any other attribute. There are no transitive dependencies between attributes and the primary key. The Order ID is the primary key that uniquely identifies each record, and the Customer ID and Product ID are foreign keys that refer to the primary keys of the Customer and Product tables, respectively.
Advantages of Normalization
Normalization is a process of organizing data in a database to reduce redundancy and improve data integrity. The main advantages are:
- Elimination of data redundancy: Normalization helps to eliminate duplicate data and reduce the amount of storage space required for the database.
- Improved data integrity: Normalization ensures that data is consistent and accurate across the database, which helps to maintain data integrity.
- Easier data maintenance: it makes it easier to update, insert, and delete data, as changes only need to be made in one place.
- Improved query performance: Normalization can improve the performance of queries by reducing the number of joins required to retrieve data.
Overall, normalization is an important process that helps to ensure that a database is well-designed and efficient.
Disadvantages of Normalization
Normalization, while having many advantages, also has some disadvantages. The main disadvantage is that it can lead to increased complexity in the database design, as it requires splitting data into multiple tables and establishing relationships between them. This can make the database more difficult to understand and maintain. Additionally, normalization can reduce query performance in some cases, as it may require more joins to retrieve data from multiple tables. Finally, it can also increase development time and effort, as it requires careful analysis and planning to ensure that the database is properly normalized.
Overall, normalization has trade-offs that need to be considered in the database design process.
Conclusion
Normalization is a powerful technique that can help you make sense of your data and optimize your database performance. By applying the rules of normal forms, you can eliminate redundancy, inconsistency, and confusion from your data, and enhance its accuracy, integrity, and usability.


